
Performance Gains from Class Production for Compound Keys
There are many places in EPL that take one or more key expressions as parameters. For instance, in the group-by clause, there can be multiple expressions. The EPL compiler, starting with version 8.2.0, builds classes to represent multiple key expressions (compound keys) as they occur. This saves heap memory and improves "hashCode" and "equals" performance.
Suppose that an event has two fields that together make up the grouping key in a group-by clause. The sample schema calls the two fields 'part0' and 'part1'. The sample schema uses object-array events but the same applies to JSON, Map and all other event types. The EPL computes the count per combination of 'part0' and 'part1' key.
@public @buseventtype create objectarray schema SampleEvent(
part0 int, part1 int);
select count(*) from SampleEvent group by part0, part1;
Internally and not visible to you the EPL compiler produces a class for the compound key that looks similar to the class here.
public class CompoundKey {
int part0;
int part1;
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
CompoundKey that = (CompoundKey) o;
if (part0 != that.part0) return false;
return part1 == that.part1;
}
public int hashCode() {
int result = part0;
result = 31 * result + part1;
return result;
}
}
To give you an idea of the performance improvement, we ran the JMH benchmark for Esper version 8.2.0 and Esper version 8.1.0. The simulator produces 1M key combinations. The result is that version 8.2.0 is quite a bit faster.
Benchmark Mode Cnt Score Error Units Version_8_2_0 thrpt 5 782292.168 ± 84810.439 ops/s Version_8_1_0 thrpt 5 668341.421 ± 1287.599 ops/s
The JMH benchmark class is pretty plain.
public class MyBenchmark {
@State(Scope.Thread)
public static class MyState {
EPRuntime runtime;
Random random = new Random(System.currentTimeMillis());
@Setup
public void setUp() {
Configuration configuration = new Configuration();
configuration.getRuntime().getThreading().setInternalTimerEnabled(false);
runtime = EPRuntimeProvider.getDefaultRuntime(configuration);
String epl =
"@public @buseventtype create objectarray schema SampleEvent(part0 int, part1 int);\n" +
"select count(*) from SampleEvent group by part0, part1;\n";
compileDeploy(runtime, epl);
}
}
@Benchmark
@Fork(value = 1, warmups = 0)
public void testMethod(MyState state) {
int part0 = next(state.random);
int part1 = next(state.random);
state.runtime.getEventService().sendEventObjectArray(new Object[] {part0, part1}, "SampleEvent");
}
private int next(Random random) {
return random.nextInt(1000);
}
private static void compileDeploy(EPRuntime runtime, String epl) {
try {
CompilerArguments args = new CompilerArguments();
args.getPath().add(runtime.getRuntimePath());
EPCompiled compiled = EPCompilerProvider.getCompiler().compile(epl, args);
runtime.getDeploymentService().deploy(compiled);
}
catch (Exception ex) {
throw new RuntimeException(ex);
}
}
}
JSON Deserialize Performance
Esper version 8.2.0 handles JSON documents directly, without the need to create a class. It does so by supporting EPL create-schema for JSON, with the EPL compiler producing a suitable streaming JSON parser and a value class with fields that hold parsed JSON values. This blog post compares the performance of Gson and Jackson with the JSON parser that the EPL compiler produces.
The tests run the java-json-benchmark which we extended to test Esper. For reference, Gson is a JSON serialization/deserialization library and so is Jackson.
The JSON string contains multiple user information such as user id (guid), age, eye color, address as well as user tags and friend information. The string is ~1k bytes in size.
{
"users": [
{
"_id": "45166552176594981065",
"index": 692815193,
"guid": "oLzFhQttjjCGmijYulZg",
"isActive": true,
"balance": "XtMtTkSfmQtyRHS1086c",
"picture": "Q8YoyJ0cL1MGFwC9bpAzQXSFBEcAUQ8lGQekvJZDeJ5C5p",
"age": 23,
"eyeColor": "XqoN9IzOBVixZhrofJpd",
"name": "xBavaMCv6j0eYkT6HMcB",
"gender": "VnuP3BaA3flaA6dLGvqO",
"company": "L9yT2IsGTjOgQc0prb4r",
"email": "rfmlFaVxGBSZFybTIKz0",
"phone": "vZsxzv8DlzimJauTSBre",
"address": "fZgFDv9tX1oonnVjcNVv",
"about": "WysqSAN1psGsJBCFSR7P",
"registered": "Lsw4RK5gtyNWGYp9dDhy",
"latitude": 2.6395313895198393,
"longitude": 110.5363758848371,
"tags": [
"Hx6qJTHe8y",
"23vYh8ILj6",
"geU64sSQgH",
"ezNI8Gx5vq"
],
"friends": [
{
"id": "3987",
"name": "dWwKYheGgTZejIMYdglXvvrWAzUqsk"
},
{
"id": "4673",
"name": "EqVIiZyuhSCkWXvqSxgyQihZaiwSra"
}
],
"greeting": "xfS8vUXYq4wzufBLP6CY",
"favoriteFruit": "KT0tVAxXRawtbeQIWAot"
},
{
"_id": "23504426278646846580",
"index": 675066974,
"guid": "MfiCc1n1WfG6d6iXcdNf",
"isActive": true,
"balance": "OQEwTOBvwK0b8dJYFpBU",
"picture": "avtMGQxSrO1h86V7KVaKaWUFZ0ooZd9GmIynRomjCjP8tEN",
"age": 33,
"eyeColor": "Fjsm1nmwyphAw7DRnfZ7",
"name": "NnjrrCj1TTObhT9gHMH2",
"gender": "ISVVoyQ4cbEjQVoFy5z0",
"company": "AfcGdkzUQMzg69yjvmL5",
"email": "mXLtlNEJjw5heFiYykwV",
"phone": "zXbn9iJ5ljRHForNOa79",
"address": "XXQUcaDIX2qpyZKtw8zl",
"about": "GBVYHdxZYgGCey6yogEi",
"registered": "bTJynDeyvZRbsYQIW9ys",
"latitude": 16.675958191062414,
"longitude": 114.20858157883556,
"tags": [],
"friends": [],
"greeting": "EQqKZyiGnlyHeZf9ojnl",
"favoriteFruit": "9aUx0u6G840i0EeKFM4Z"
}
]
}
Listed below is the EPL schema for the JSON document.
create json schema Friend(id string, name string);
create json schema User(_id string,
index int,
guid string,
isActive string,
balance string,
picture string,
age int,
eyeColor string,
name string,
gender string,
company string,
email string,
phone string,
address string,
about string,
registered string,
latitude double,
longitude double,
tags string[],
friends Friend[],
greeting string,
favoriteFruit string);
create json schema Users(users User[]);
The benchmark compiles and deploys the EPL. It obtains the event sender to parse JSON without actually processing the event. The steps for this are in the next few line.
compileDeploy(runtime, schema); // compile and deploy schema (see doc)
EventSenderJson sender = (EventSenderJson)
runtime.getEventService().getEventSender("Users");
sender.parse(json); // json string as above
We extended the java-json-benchmark project to run Esper. The java-json-benchmark uses JMH and can run the different libraries. The results of the run is below.
.\run.ps1 deser --apis databind --libs "esper,gson,jackson" Benchmark Mode Cnt Score Error Units Deserialization.gson thrpt 20 380355.156 ± 102952.861 ops/s Deserialization.esper thrpt 20 625104.578 ± 124892.697 ops/s Deserialization.jackson thrpt 20 703692.069 ± 166341.185 ops/s
It is not clear why Gson performance looks low. The complete output is below.
Run progress: 0.00% complete, ETA 00:01:10 Fork: 1 of 2 Warmup Iteration 1: SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder". SLF4J: Defaulting to no-operation (NOP) logger implementation SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details. Using SEED=355928074 as seed for Random 356831.878 ops/s Warmup Iteration 2: 486136.353 ops/s Warmup Iteration 3: 515357.952 ops/s Warmup Iteration 4: 509446.072 ops/s Warmup Iteration 5: 518303.540 ops/s Iteration 1: 517984.589 ops/s Iteration 2: 518057.298 ops/s Iteration 3: 517874.770 ops/s Iteration 4: 520368.313 ops/s Iteration 5: 504031.483 ops/s Iteration 6: 259520.276 ops/s Iteration 7: 141100.628 ops/s Iteration 8: 196268.361 ops/s Iteration 9: 228216.651 ops/s Iteration 10: 260322.078 ops/s Run progress: 50.00% complete, ETA 00:00:39 Fork: 2 of 2 Warmup Iteration 1: SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder". SLF4J: Defaulting to no-operation (NOP) logger implementation SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details. Using SEED=355928074 as seed for Random 193367.787 ops/s Warmup Iteration 2: 280659.932 ops/s Warmup Iteration 3: 302554.536 ops/s Warmup Iteration 4: 322162.441 ops/s Warmup Iteration 5: 329478.408 ops/s Iteration 1: 341587.662 ops/s Iteration 2: 353809.794 ops/s Iteration 3: 364638.181 ops/s Iteration 4: 384033.414 ops/s Iteration 5: 402530.792 ops/s Iteration 6: 412963.221 ops/s Iteration 7: 423726.426 ops/s Iteration 8: 431531.785 ops/s Iteration 9: 440825.460 ops/s Iteration 10: 448492.988 ops/s Result "com.github.fabienrenaud.jjb.databind.Deserialization.gson": 383394.208 ±(99.9%) 99933.179 ops/s [Average] (min, avg, max) = (141100.628, 383394.208, 520368.313), stdev = 115083.198 CI (99.9%): [283461.029, 483327.387] (assumes normal distribution) Run complete. Total time: 00:01:19 Benchmark Mode Cnt Score Error Units Deserialization.gson thrpt 20 383394.208 ± 99933.179 ops/s java -server -XX:+AggressiveOpts -Xms2g -Xmx2g -jar build\libs\app.jar deser --apis databind --libs esper,gson,jackson JMH version: 1.20 VM version: JDK 1.8.0_192, VM 25.192-b12 VM invoker: C:\Java\jdk1.8.0_192\jre\bin\java.exe VM options: Warmup: 5 iterations, 1 s each Measurement: 10 iterations, 3 s each Timeout: 10 min per iteration Threads: 16 threads, will synchronize iterations Benchmark mode: Throughput, ops/time Benchmark: com.github.fabienrenaud.jjb.databind.Deserialization.gson Run progress: 0.00% complete, ETA 00:03:30 Fork: 1 of 2 Warmup Iteration 1: SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder". SLF4J: Defaulting to no-operation (NOP) logger implementation SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details. Using SEED=355928074 as seed for Random 288279.935 ops/s Warmup Iteration 2: 489983.172 ops/s Warmup Iteration 3: 520986.946 ops/s Warmup Iteration 4: 524690.847 ops/s Warmup Iteration 5: 524284.236 ops/s Iteration 1: 526489.947 ops/s Iteration 2: 525270.990 ops/s Iteration 3: 526443.131 ops/s Iteration 4: 513476.515 ops/s Iteration 5: 153916.529 ops/s Iteration 6: 168760.049 ops/s Iteration 7: 210875.579 ops/s Iteration 8: 237990.523 ops/s Iteration 9: 273769.762 ops/s Iteration 10: 298343.511 ops/s Run progress: 16.67% complete, ETA 00:03:15 Fork: 2 of 2 Warmup Iteration 1: SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder". SLF4J: Defaulting to no-operation (NOP) logger implementation SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details. Using SEED=355928074 as seed for Random 197768.475 ops/s Warmup Iteration 2: 306685.739 ops/s Warmup Iteration 3: 337464.437 ops/s Warmup Iteration 4: 347067.561 ops/s Warmup Iteration 5: 350076.319 ops/s Iteration 1: 364416.146 ops/s Iteration 2: 381411.513 ops/s Iteration 3: 396296.144 ops/s Iteration 4: 406238.196 ops/s Iteration 5: 408165.895 ops/s Iteration 6: 422488.775 ops/s Iteration 7: 433276.809 ops/s Iteration 8: 445738.057 ops/s Iteration 9: 453633.056 ops/s Iteration 10: 460101.988 ops/s Result "com.github.fabienrenaud.jjb.databind.Deserialization.gson": 380355.156 ±(99.9%) 102952.861 ops/s [Average] (min, avg, max) = (153916.529, 380355.156, 526489.947), stdev = 118560.668 CI (99.9%): [277402.295, 483308.017] (assumes normal distribution) JMH version: 1.20 VM version: JDK 1.8.0_192, VM 25.192-b12 VM invoker: C:\Java\jdk1.8.0_192\jre\bin\java.exe VM options: Warmup: 5 iterations, 1 s each Measurement: 10 iterations, 3 s each Timeout: 10 min per iteration Threads: 16 threads, will synchronize iterations Benchmark mode: Throughput, ops/time Benchmark: com.github.fabienrenaud.jjb.databind.Deserialization.jackson Run progress: 33.33% complete, ETA 00:02:37 Fork: 1 of 2 Warmup Iteration 1: SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder". SLF4J: Defaulting to no-operation (NOP) logger implementation SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details. Using SEED=355928074 as seed for Random 474878.945 ops/s Warmup Iteration 2: 802966.481 ops/s Warmup Iteration 3: 712858.027 ops/s Warmup Iteration 4: 740797.359 ops/s Warmup Iteration 5: 763551.499 ops/s Iteration 1: 782842.724 ops/s Iteration 2: 886217.925 ops/s Iteration 3: 897024.236 ops/s Iteration 4: 906403.846 ops/s Iteration 5: 922395.550 ops/s Iteration 6: 885245.860 ops/s Iteration 7: 826431.459 ops/s Iteration 8: 844156.887 ops/s Iteration 9: 854776.515 ops/s Iteration 10: 870187.841 ops/s Run progress: 50.00% complete, ETA 00:01:57 Fork: 2 of 2 Warmup Iteration 1: SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder". SLF4J: Defaulting to no-operation (NOP) logger implementation SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details. Using SEED=355928074 as seed for Random 546879.887 ops/s Warmup Iteration 2: 849142.467 ops/s Warmup Iteration 3: 335546.405 ops/s Warmup Iteration 4: 232004.319 ops/s Warmup Iteration 5: 236806.194 ops/s Iteration 1: 304245.449 ops/s Iteration 2: 398422.848 ops/s Iteration 3: 448193.203 ops/s Iteration 4: 503593.337 ops/s Iteration 5: 539268.939 ops/s Iteration 6: 581295.972 ops/s Iteration 7: 616766.077 ops/s Iteration 8: 640036.098 ops/s Iteration 9: 667639.232 ops/s Iteration 10: 698697.385 ops/s Result "com.github.fabienrenaud.jjb.databind.Deserialization.jackson": 703692.069 ±(99.9%) 166341.185 ops/s [Average] (min, avg, max) = (304245.449, 703692.069, 922395.550), stdev = 191558.755 CI (99.9%): [537350.885, 870033.254] (assumes normal distribution) JMH version: 1.20 VM version: JDK 1.8.0_192, VM 25.192-b12 VM invoker: C:\Java\jdk1.8.0_192\jre\bin\java.exe VM options: Warmup: 5 iterations, 1 s each Measurement: 10 iterations, 3 s each Timeout: 10 min per iteration Threads: 16 threads, will synchronize iterations Benchmark mode: Throughput, ops/time Benchmark: com.github.fabienrenaud.jjb.databind.Deserialization.jackson_afterburner Run progress: 66.67% complete, ETA 00:01:18 Fork: 1 of 2 Warmup Iteration 1: SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder". SLF4J: Defaulting to no-operation (NOP) logger implementation SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details. Using SEED=355928074 as seed for Random 577052.249 ops/s Warmup Iteration 2: 837639.921 ops/s Warmup Iteration 3: 851474.733 ops/s Warmup Iteration 4: 873343.762 ops/s Warmup Iteration 5: 873135.520 ops/s Iteration 1: 889379.290 ops/s Iteration 2: 914258.396 ops/s Iteration 3: 928132.585 ops/s Iteration 4: 953161.613 ops/s Iteration 5: 952915.538 ops/s Iteration 6: 958374.194 ops/s Iteration 7: 977448.096 ops/s Iteration 8: 1009370.292 ops/s Iteration 9: 1025722.026 ops/s Iteration 10: 1037452.536 ops/s Run progress: 83.33% complete, ETA 00:00:39 Fork: 2 of 2 Warmup Iteration 1: SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder". SLF4J: Defaulting to no-operation (NOP) logger implementation SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details. Using SEED=355928074 as seed for Random 712829.114 ops/s Warmup Iteration 2: 1070309.076 ops/s Warmup Iteration 3: 1027631.655 ops/s Warmup Iteration 4: 905102.951 ops/s Warmup Iteration 5: 923147.446 ops/s Iteration 1: 942076.760 ops/s Iteration 2: 945732.126 ops/s Iteration 3: 955351.526 ops/s Iteration 4: 973549.500 ops/s Iteration 5: 999500.944 ops/s Iteration 6: 1020378.209 ops/s Iteration 7: 1024975.429 ops/s Iteration 8: 1030572.193 ops/s Iteration 9: 1052722.004 ops/s Iteration 10: 996312.536 ops/s Result "com.github.fabienrenaud.jjb.databind.Deserialization.jackson_afterburner": 979369.290 ±(99.9%) 39243.509 ops/s [Average] (min, avg, max) = (889379.290, 979369.290, 1052722.004), stdev = 45192.883 CI (99.9%): [940125.781, 1018612.799] (assumes normal distribution) Run complete. Total time: 00:03:55 Benchmark Mode Cnt Score Error Units Deserialization.gson thrpt 20 380355.156 ± 102952.861 ops/s Deserialization.esper thrpt 20 625104.578 ± 124892.697 ops/s Deserialization.jackson thrpt 20 703692.069 ± 166341.185 ops/s Deserialization.jackson_afterburner thrpt 20 979369.290 ± 39243.509 ops/s
Performance Gains Compiling EPL Expressions to Byte Code with Version 8
The Esper version 8 compiler produces JVM byte code from common EPL expressions such as a+b. For the purpose of computing the sum these are the steps:
- Downcast the event underlying object
- Obtain the values for “a†and “b†by calling a method on the event underlying object
- Perform the addition
- Stuff the result in an output event
With regard to step 1, the Esper compiler makes sure to downcast each event object just once regardless of the number of event properties in a given EPL expression.
Relating to step 2, the Esper compiler generates byte code that calls the relevant method. There is no indirection at runtime since the compiled code is specific to the event underlying object.
About step 3, the simplified the byte code tends to give the Java platform just-in-time compiler a chance to do its own optimizations.
As to step 4, depending on the nature of the output event (POJO, object-array etc.) the compiler generates byte code that stuffs the result into the target directly (setter, constructor, index-based array write, or map put depending on the output event underlying object, or other).
Let’s say there is an event that has 100 properties that need to be added up. The sample event for the discussion is:
public static class TestEvent {
private int v0;
private int v1;
private int v2;
private int v3;
... and so on....
public int getV0() { return v0; }
public int getV1() { return v1; }
public int getV2() { return v2; }
public int getV3() { return v3; }
... and so on....
}Now let’s get to the EPL that adds up the 100 values of each event. It is straight select.
select v0 + v1 + v2 + v3 + v4 + v5 + v6 + v7 + v8 + v9 + v10 + v11 +
v12 + v13 + v14 + v15 + v16 + v17 + v18 + v19 + v20 + v21 + v22 +
v23 + v24 + v25 + v26 + v27 + v28 + v29 + v30 + v31 + v32 + v33 +
v34 + v35 + v36 + v37 + v38 + v39 + v40 + v41 + v42 + v43 + v44 +
v45 + v46 + v47 + v48 + v49 + v50 + v51 + v52 + v53 + v54 + v55 +
v56 + v57 + v58 + v59 + v60 + v61 + v62 + v63 + v64 + v65 + v66 +
v67 + v68 + v69 + v70 + v71 + v72 + v73 + v74 + v75 + v76 + v77 +
v78 + v79 + v80 + v81 + v82 + v83 + v84 + v85 + v86 + v87 + v88 +
v89 + v90 + v91 + v92 + v93 + v94 + v95 + v96 + v97 + v98 +
v99 as c0 from TestEventThe EPL, above, doesn’t hold any event or other information in memory and therefore the heap size can be tiny if we wanted to. The test setup is JVM 1.8.0_192, heap 256m (-Xms256m –Xmx256m), Intel i7 7700HQ@2.80 GHz.
Voila. Here are the performance test results:
| Release | Milliseconds Processing 10 Million Events |
| Version 8.1 | 5422 millis |
| Version 6.1 | 15141 millis |
The code for Esper version 8.1 is:
String epl = "@public @buseventtype create schema TestEvent as " + TestEvent.class.getName() + ";\n" +
"select v0+v1+v2+v3+v4+v5+v6+v7+v8+v9+v10+v11+v12+v13+v14+v15+v16+v17+v18+v19+v20+\n" +
"v21+v22+v23+v24+v25+v26+v27+v28+v29+v30+v31+v32+v33+v34+v35+v36+v37+v38+v39+v40+\n" +
"v41+v42+v43+v44+v45+v46+v47+v48+v49+v50+v51+v52+v53+v54+v55+v56+v57+v58+v59+v60+\n" +
"v61+v62+v63+v64+v65+v66+v67+v68+v69+v70+v71+v72+v73+v74+v75+v76+v77+v78+v79+v80+\n" +
"v81+v82+v83+v84+v85+v86+v87+v88+v89+v90+v91+v92+v93+v94+v95+v96+v97+v98+v99 as c0 from TestEvent;\n";
CompilerArguments args = new CompilerArguments();
EPCompiled compiled = EPCompilerProvider.getCompiler().compile(epl, args);
EPRuntime runtime = EPRuntimeProvider.getDefaultRuntime();
EPDeployment deployment = runtime.getDeploymentService().deploy(compiled);
// we add a listener since realistically there would be one
deployment.getStatements()[1].addListener((ne, oe, stmr, r) -> {});
EventSender sender = runtime.getEventService().getEventSender("TestEvent");
// process events
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
sender.sendEvent(new TestEvent());
}
long delta = System.currentTimeMillis() - start;
System.out.println("Completed in " + delta + " milliseconds");The code for Esper version 6.1 is:
String epl = "create schema TestEvent as " + TestEvent.class.getName() + ";\n" +
"@name('out') select v0+v1+v2+v3+v4+v5+v6+v7+v8+v9+v10+v11+v12+v13+v14+v15+v16+v17+v18+v19+v20+\n" +
"v21+v22+v23+v24+v25+v26+v27+v28+v29+v30+v31+v32+v33+v34+v35+v36+v37+v38+v39+v40+\n" +
"v41+v42+v43+v44+v45+v46+v47+v48+v49+v50+v51+v52+v53+v54+v55+v56+v57+v58+v59+v60+\n" +
"v61+v62+v63+v64+v65+v66+v67+v68+v69+v70+v71+v72+v73+v74+v75+v76+v77+v78+v79+v80+\n" +
"v81+v82+v83+v84+v85+v86+v87+v88+v89+v90+v91+v92+v93+v94+v95+v96+v97+v98+v99 as c0 from TestEvent;\n";
EPServiceProvider epService = EPServiceProviderManager.getDefaultProvider();
epService.getEPAdministrator().getDeploymentAdmin().parseDeploy(epl);
// we add a listener since realistically there would be one
epService.getEPAdministrator().getStatement("out").addListener((ne, oe) -> {});
EventSender sender = epService.getEPRuntime().getEventSender("TestEvent");
// process events
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
sender.sendEvent(new TestEvent());
}
long delta = System.currentTimeMillis() - start;
System.out.println("Completed in " + delta + " milliseconds");How the Esper Compiler Reduces Heap Memory and Improves Performance by Generating a Class Representing an Aggregation Row
The aggregation function “avg†returns the average of a numeric value. The runtime maintains a count and a total for each average that is must compute.
To illustrate, imagine events that have 10 numeric values:
create objectarray schema SampleEvent (key int, v0 int, v1 int, v2 int, v3 int, v4 int, v5 int, v6 int, v7 int, v8 int, v9 int);The next EPL outputs the average of each value considering all events that arrives so far:
select key, avg(v0), avg(v1), avg(v2), avg(v3), avg(v4), avg(v5), avg(v6), avg(v7), avg(v8), avg(v9) from SampleEvent group by key;In version 8 of Esper the compiler generates a class that represents the 10 averages. This class becomes visible when we turn on logging of generated classes or we have the compiler output the code into a separate directory (see doc).
The Esper 8 compiler generates a class similar to this:
static class AggRow implements AggregationRow {
long cnt0;
int sum0;
long cnt1;
int sum1;
long cnt2;
int sum2;
long cnt3;
int sum3;
long cnt4;
int sum4;
long cnt5;
int sum5;
long cnt6;
int sum6;
long cnt7;
int sum7;
long cnt8;
int sum8;
long cnt9;
int sum9;
// leaving methods away for now
}
The compiler also generates code to update the averages from the events coming in and going out, and it generates code to query the averages. All this is used internally by the runtime.
The reason that the compiler generates the class it is that by having all aggregation state next to each other in fields, without any additional objects that are allocated, is optimal for heap memory use. It also has performance advantages when adding and removing events and querying as the generated code eliminates virtual calls and down-casts and crossing object boundaries that would otherwise be necessary.
We tested memory use and performance adding 10 million rows. The test setup is JVM 1.8.0_192, heap 4G (-Xms4g –Xmx4g), Intel i7 7700HQ@2.80 GHz, 16 GB system memory. The code for Esper 8.1 and Esper 7.1 is below. Measuring memory use was done with jmap, jconsole and a memory measuring agent (Jamm, multiple for comparison).
Here is the table comparing the versions:
| Esper Version | Memory in GB | Load Time in Milliseconds (10 million events) |
| Version 8.1 | 1.91 GB | 7300 msec |
| Version 7.1 | 1.99 GB | 8327 msec |
The Esper 8.1 code is:
String epl = "@public @buseventtype create objectarray schema SampleEvent (key int, v0 int, v1 int, v2 int, v3 int, v4 int, v5 int, v6 int, v7 int, v8 int, v9 int);\n" +
"select key, avg(v0), avg(v1), avg(v2), avg(v3), avg(v4), avg(v5), avg(v6), avg(v7), avg(v8), avg(v9) from SampleEvent group by key;\n";
EPCompiled compiled = EPCompilerProvider.getCompiler().compile(epl, null);
EPRuntime runtime = EPRuntimeProvider.getDefaultRuntime();
EPDeployment deployment = runtime.getDeploymentService().deploy(compiled);
// we add a listener since realistically there would be one
deployment.getStatements()[0].addListener((ne, oe, stmr, r) -> {});
EventSender sender = runtime.getEventService().getEventSender("SampleEvent");
// load events
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
sender.sendEvent(new Object[]{i, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1});
}
long delta = System.currentTimeMillis() - start;
System.out.println("Loaded groups, done in " + delta + " milliseconds");The Esper 7.1 code is:
String epl = "create objectarray schema SampleEvent (key int, v0 int, v1 int, v2 int, v3 int, v4 int, v5 int, v6 int, v7 int, v8 int, v9 int);\n" +
"@name('out') select key, avg(v0), avg(v1), avg(v2), avg(v3), avg(v4), avg(v5), avg(v6), avg(v7), avg(v8), avg(v9) from SampleEvent group by key;\n";
EPServiceProvider epService = EPServiceProviderManager.getDefaultProvider();
epService.getEPAdministrator().getDeploymentAdmin().parseDeploy(epl);
// we add a listener since realistically there would be one
epService.getEPAdministrator().getStatement("out").addListener((ne, oe) -> {});
EventSender sender = epService.getEPRuntime().getEventSender("SampleEvent");
// load events
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
sender.sendEvent(new Object[]{i, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1});
}
long delta = System.currentTimeMillis() - start;
System.out.println("Loaded groups, done in " + delta + " milliseconds");7+ Million Events-Per-Second
Starting with Esper version 8 the compiler generates byte code and the runtime loads the byte code and hosts the execution. The compiler of version 8 dynamically creates a class to represent the aggregation row and that speeds up processing even further as compared to version 7.x. This technique leads to higher performance as it eliminates branches and virtual calls and allows the JVM's JIT to perform further optimizations. In version 7.x we had already made optimizations and generated some byte code for expression evaluation, but version 8 is all byte code.
We measured a query and found Esper version 8.1.0 the performance reaches about 7.1 million events per second. This compares to about 6.1 million events per second for Esper version 7.1.0 and about 4 million events per second for Esper version 6.1.0.
The measurement is shown in the below table. Read on for the explanation and code.
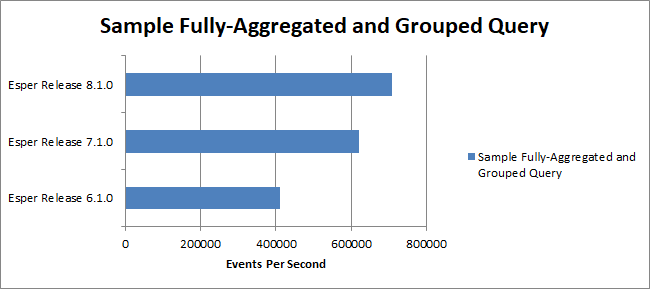
The EPL query is this one.
select p0, sum(p1) from SampleEvent group by p0 having sum(p1) >= 100000000
This query totals up a field and compares it against 100 million. The code processes 100 million events.
The test setup is JVM 1.8.0_121, heap 256M (-Xms256m -Xmx256m), Intel i7 7700HQ@2.80 GHz, 16 GB system memory.
The complete test code is not that much. It's safe to measure total time since sendEvent is not an asynchronous operation. CPU utilization is 1 CPU to 100%. This test is not written to use multiple threads.
The below code is for testing against version 8.
String epl = "@public @buseventtype create objectarray schema SampleEvent (p0 string, p1 long);\n" +
"select p0, sum(p1) from SampleEvent group by p0 having sum(p1) >= 100000000;\n";
EPCompiled compiled = EPCompilerProvider.getCompiler().compile(epl, null);
EPRuntime runtime = EPRuntimeProvider.getDefaultRuntime();
EPDeployment deployment = runtime.getDeploymentService().deploy(compiled);
SupportUpdateListener listener = new SupportUpdateListener();
deployment.getStatements()[1].addListener(listener);
EventSender sender = runtime.getEventService().getEventSender("SampleEvent");
// warm-up
for (int i = 0; i < 100000; i++) {
sender.sendEvent(new Object[]{"G1", 1L});
}
// measure
long start = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
sender.sendEvent(new Object[]{"G2", 1L});
}
long delta = System.currentTimeMillis() - start;
System.out.println("Delta " + delta + " milliseconds at " + (100000000/delta)*1000 + " per second");
System.out.println("Listener received group: " + listener.assertOneGetNewAndReset().get("p0"));
The below code is for testing against version 7.x and version 6.x (there were API changes between version 8.x and version 7.x).
EPServiceProvider epService = EPServiceProviderManager.getDefaultProvider();
epService.getEPAdministrator().createEPL("create objectarray schema SampleEvent (p0 string, p1 long)");
EPStatement stmt = epService.getEPAdministrator().createEPL("select p0, sum(p1) from SampleEvent group by p0 having sum(p1) >= 100000000");
SupportUpdateListener listener = new SupportUpdateListener();
stmt.addListener(listener);
EventSender sender = epService.getEPRuntime().getEventSender("SampleEvent");
// warm-up
for (int i = 0; i < 100000; i++) {
sender.sendEvent(new Object[]{"G1", 1L});
}
// measure
long start = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
sender.sendEvent(new Object[]{"G2", 1L});
}
long delta = System.currentTimeMillis() - start;
System.out.println("Delta: " + delta);
System.out.println("Listener received group: " + listener.assertOneGetNewAndReset().get("p0"));
Compiling Streaming SQL to Byte Code with Esper Complex Event Processing
Today, the Esper team is proud to announce the first compiler that turns Streaming SQL into JVM byte code, available with the just-released Esper version 8.0.0 as of November 21, 2018.
Streaming SQL has been around since the year 2003, when commercial vendors started providing Complex Event Processing products [1, see Streambase in 2003, Coral8 and Aleri in 2006].
Esper is the first open-source implementation of Streaming SQL and Complex Event Processing and had its first release in 2006 [1, 2]. Esper is open-source under the GPLv2 license.
The Esper compiler compiles Streaming SQL into native JVM byte code. The Esper runtime loads the byte code, dynamically and at runtime, to execute for arriving events. Internally, the Esper runtime manages data structures and indexes to quickly match incoming events and time to queries and to process the raw data, allowing queries to produce output to callbacks with near-zero latency and excellent throughput.
Esper’s implementation of Streaming SQL is called the Event Processing Language (EPL). It is a declarative, data-oriented language for dealing with high frequency time-based event data. EPL is compliant to the SQL-92 standard and extended for analyzing series of events and in respect to time [3].
Complex Event Processing is technology that combines data from multiple sources and considers how time passes in order to infer events or patterns that suggest more complicated circumstances. The goal is to take in raw data and identify meaningful events (such as opportunities or threats) and respond to them as quickly as possible (source: Wikipedia).
Streaming SQL is related to Complex Event Processing in that SQL is the foundation for the language that ingests streams and analyzes events and time.
Compiling Streaming SQL to JVM byte code allows optimization to take place at compile-time and at runtime. Compile-time optimizations include co-location of objects, which is reducing heap memory footprint, and elimination of casts. Compiling to byte code allows the Java just-in-time compiler to turn byte code into native code [4]. Esper allows compiling, deploying and un-deploying queries at runtime.